在互联网日益发达的今天,我们经常需要保存网页内容以便后续查阅或离线阅读。下载网页不仅能够帮助我们保存有价值的信息,还能在没有网络连接的情况下访问这些信息。本文将详细介绍几种常见的下载网页的方法。
1. 使用浏览器自带功能
大多数现代浏览器都内置了保存当前页面的功能,这通常是下载网页最简单快捷的方式之一。
在chrome中保存网页:
- 打开你想要保存的网页。
- 点击右上角的三个点图标打开菜单。
- 选择“更多工具” > “将页面另存为pdf”。这将把整个页面保存为pdf文件,适合用于打印或者离线查看。
- 如果你希望保存为html格式,可以使用“检查”功能找到页面源代码,然后复制并粘贴到一个新的html文件中。
在firefox中保存网页:
- 打开网页后,点击菜单按钮(三条横线图标)。
- 选择“另存为” > “网页,完整”来保存整个页面包括图片和样式表;或选择“网页,仅html”来只保存html文档。
2. 使用专门的网页抓取软件
对于需要大量下载网页内容的情况,手动操作可能效率低下,这时可以考虑使用一些专业的网页抓取工具,如httrack、sitesucker等。
httrack使用步骤:
- 下载并安装httrack。
- 启动程序,设置项目名称和保存路径。
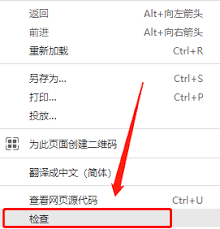
- 输入目标网站地址,设置下载范围和其他选项。
- 开始下载过程。
3. 利用命令行工具
对于技术爱好者而言,使用命令行工具是一种更为高级的方法。例如,`wget` 是一个非常强大的命令行下载工具,支持递归下载整个网站。
使用wget下载网页:
- 打开命令行界面。
- 输入命令:`wget -r -p -k -e http://example.com`。这里,`-r`表示递归下载,`-p`表示下载所有页面显示所需的内容,`-k`转换链接以便离线浏览,`-e`处理服务器端脚本生成的html文件。
4. 利用浏览器插件
还有一些专门设计用来辅助用户下载网页内容的浏览器插件,比如“webpage screenshot”(网页截图)插件可以帮助用户快速截取整个网页作为图片保存。
小结
下载网页是一项实用技能,无论你是出于学术研究、个人兴趣还是商业用途,掌握几种有效的下载方法都将大大提升你的工作效率。根据不同的需求选择最适合自己的方式,无论是简单的浏览器内置功能还是更复杂的软件工具,都能让你轻松获取所需的信息。